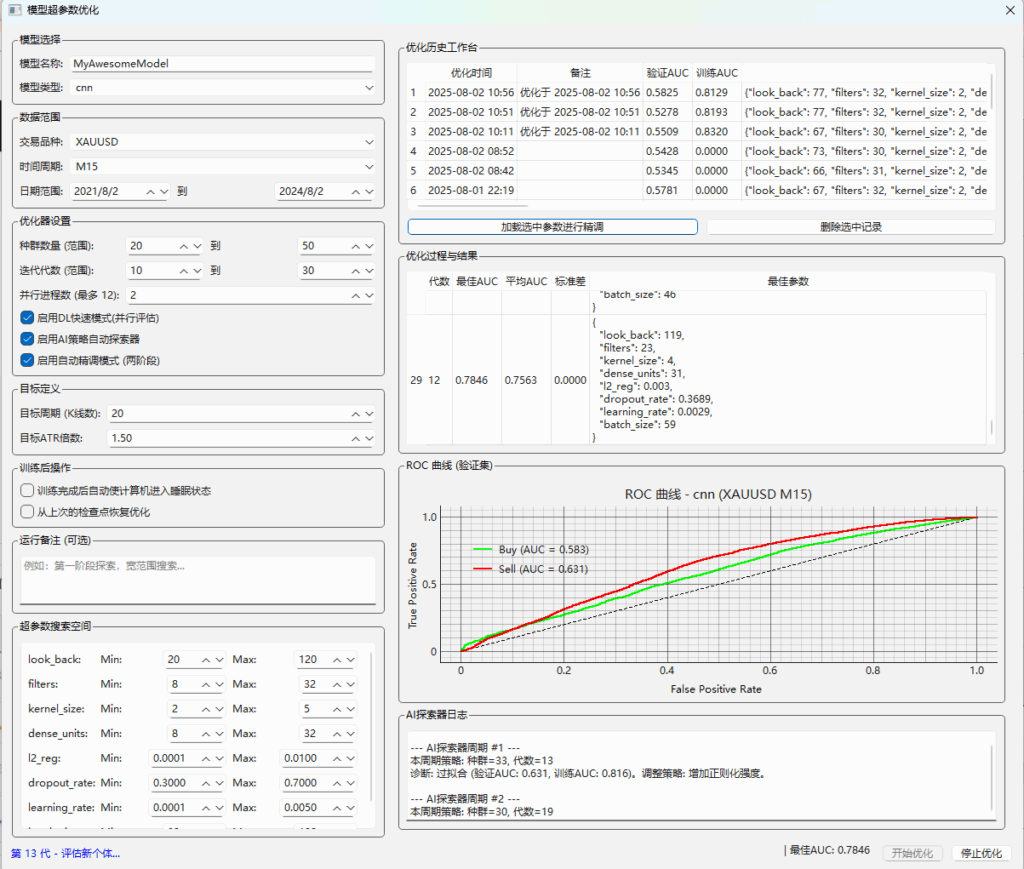
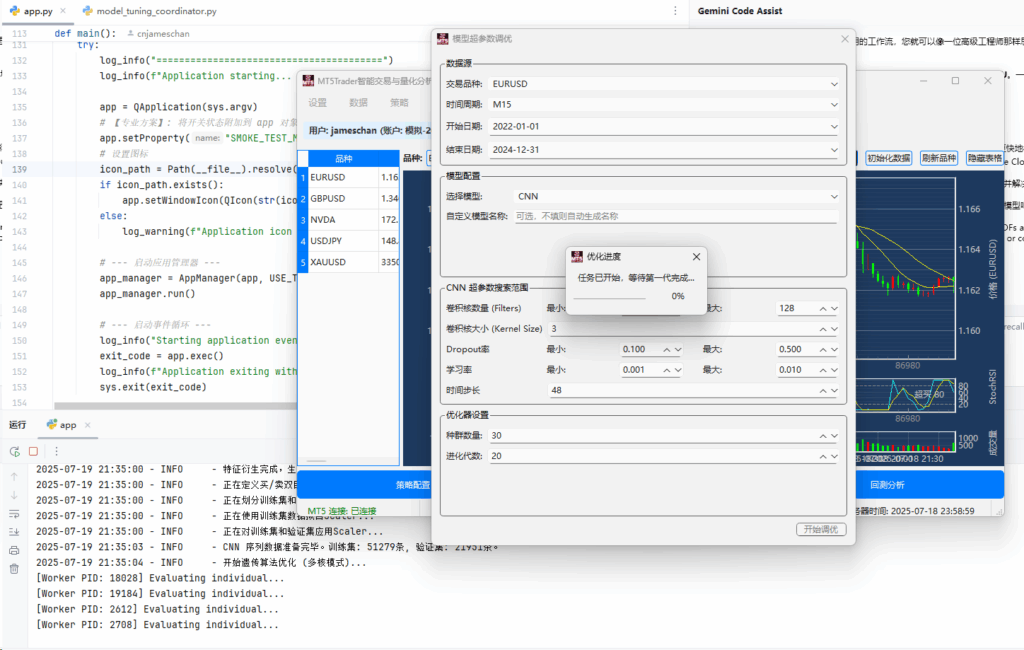
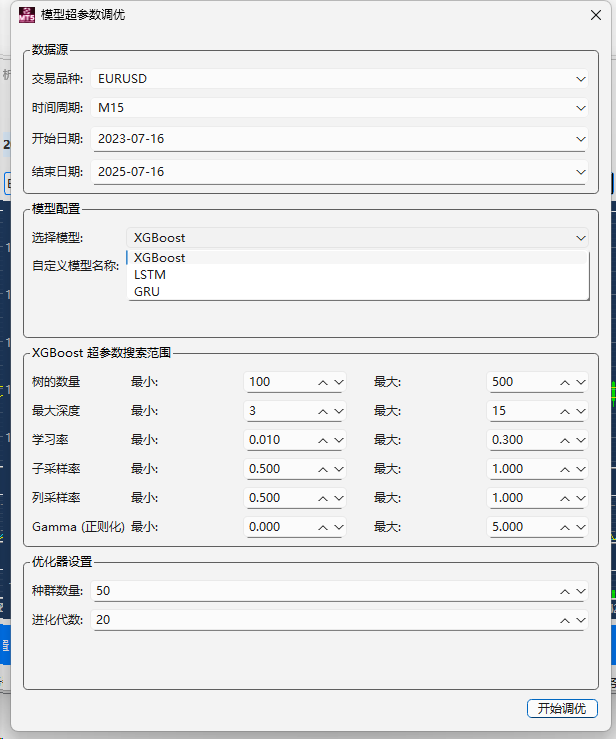
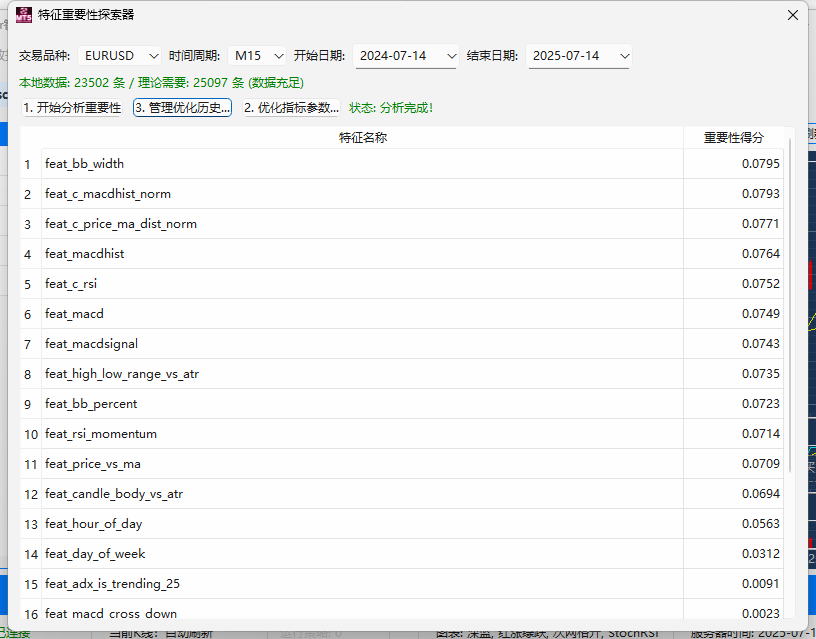
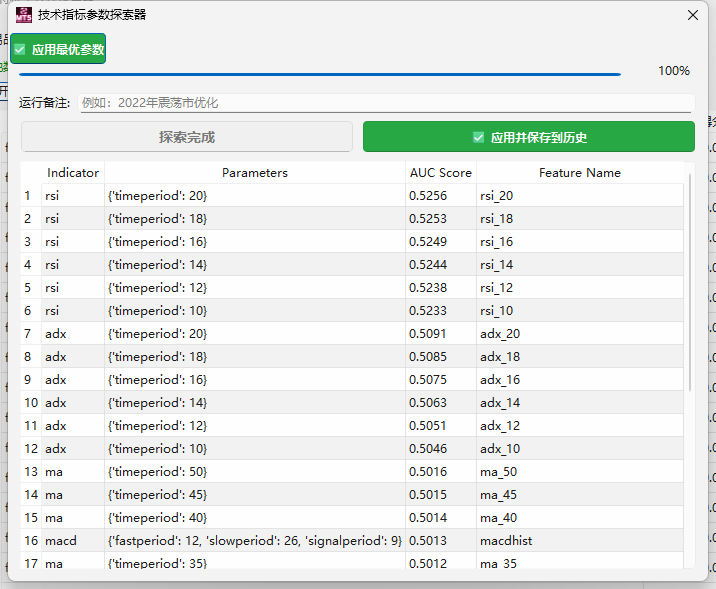
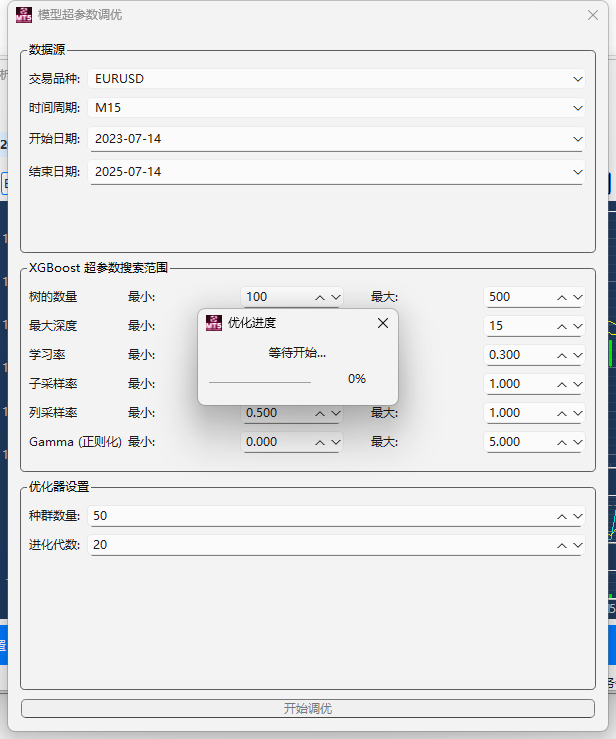
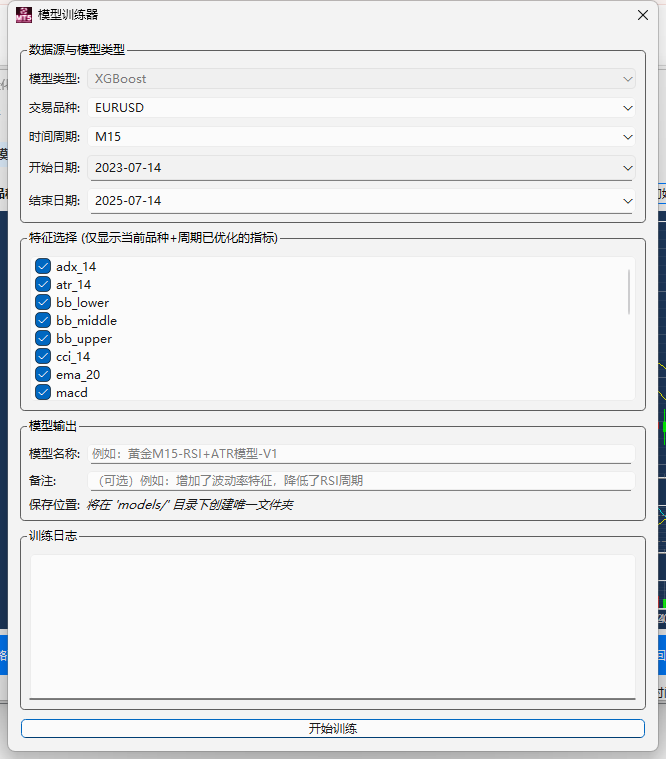
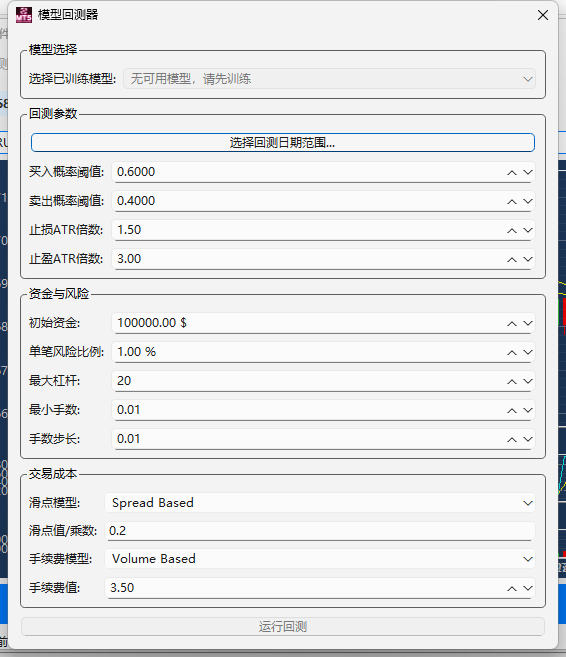
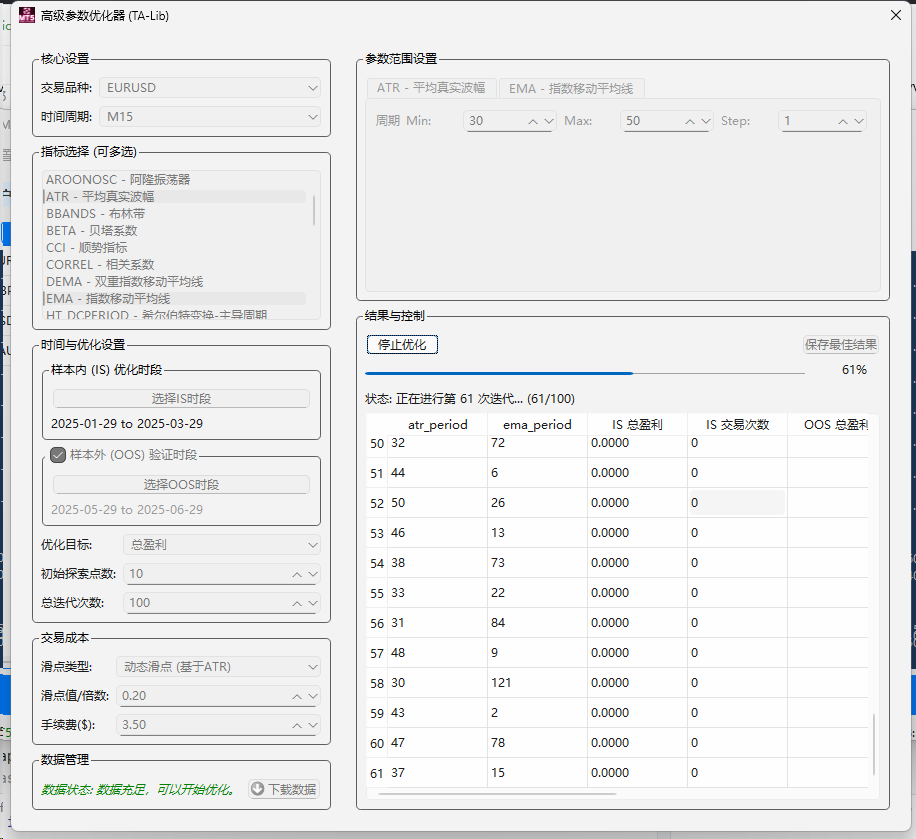
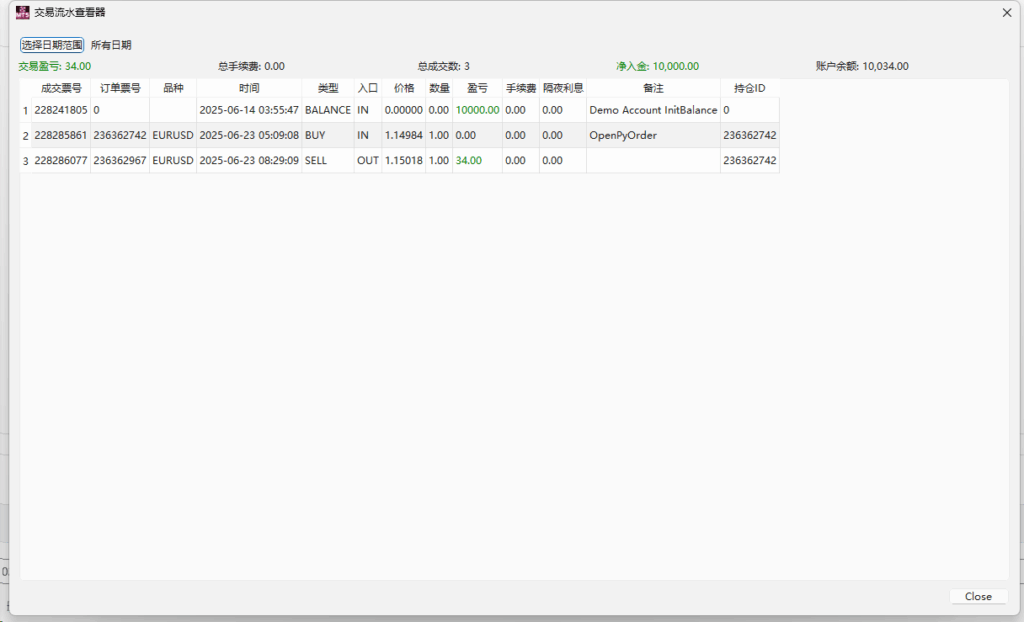
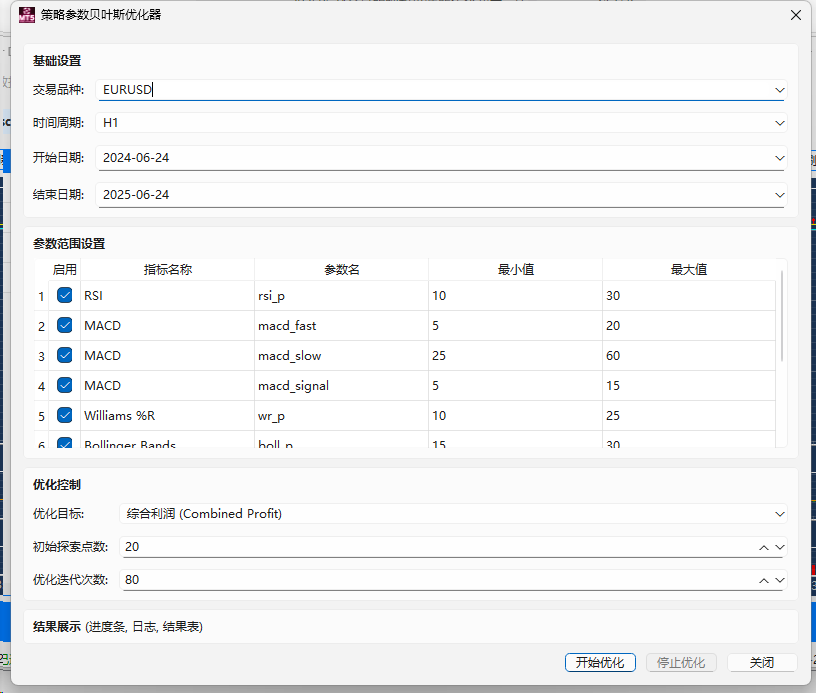
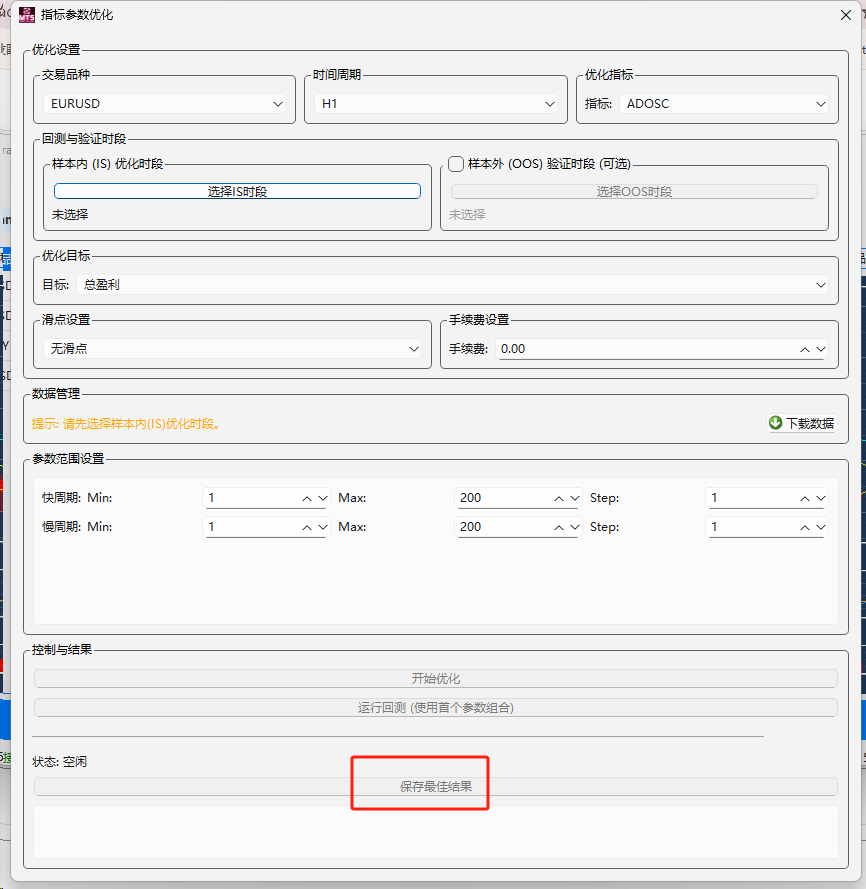
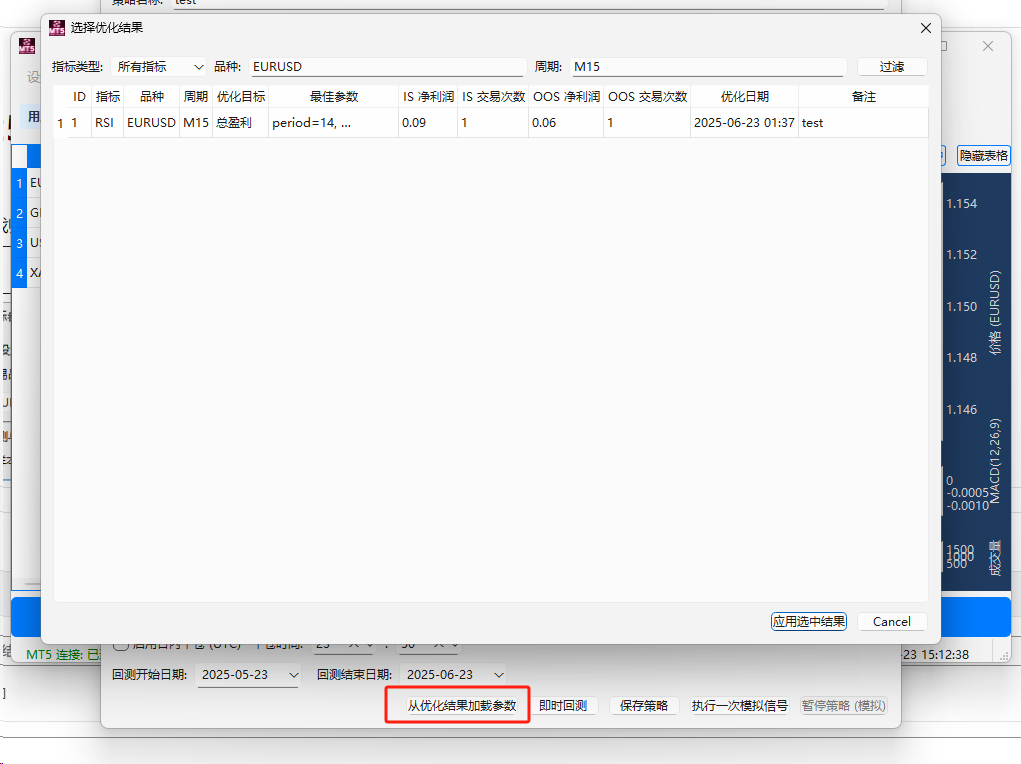
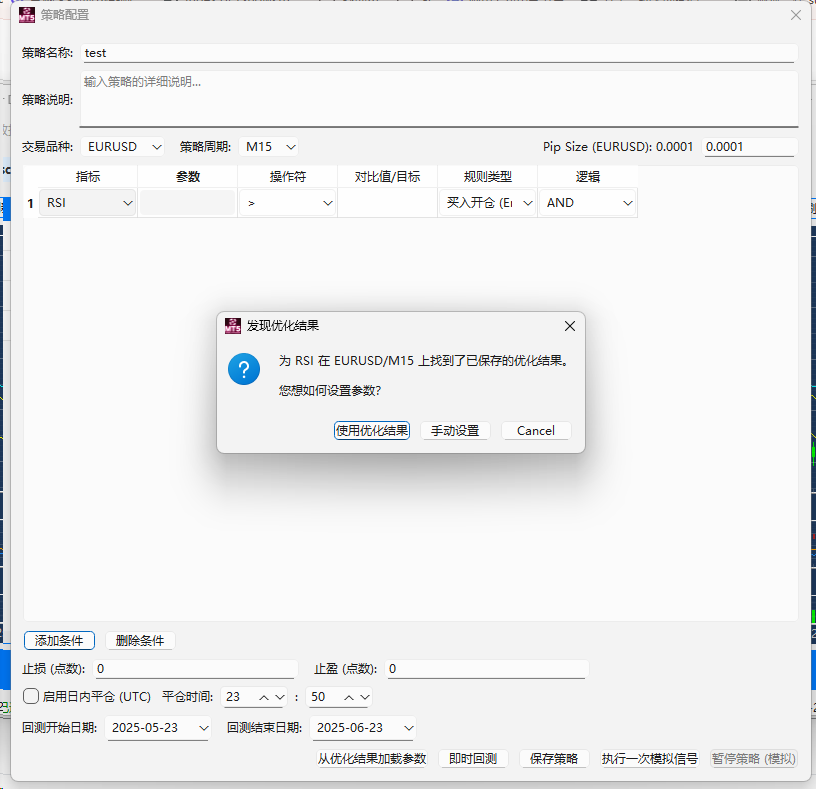
pandas-ta 是一个直接构建于 Pandas DataFrame 之上的技术分析库,这使得它非常易于与 Pandas 工作流集成,使用简单直观的接口来计算各种技术指标,可以直接添加结果到现有的 DataFrame 中,便于数据处理和可视化。本来是打算用于贝叶斯优化中用于计算和返回方便,但是发现当前官方提供的版本0.3.14b0好像很多方便的功能已经不提供了,检索开发者的github,发现“Pandas TA has moved!The current version is 0.4.25b with a pip release available after July 1st, 2025. Future releases after July 1st, 2025 will be subject to paid releases for businesses and organizations and subscription-based options for others.” 已经关闭原项目,并准备在25年7月提供订阅(付费)。